 |
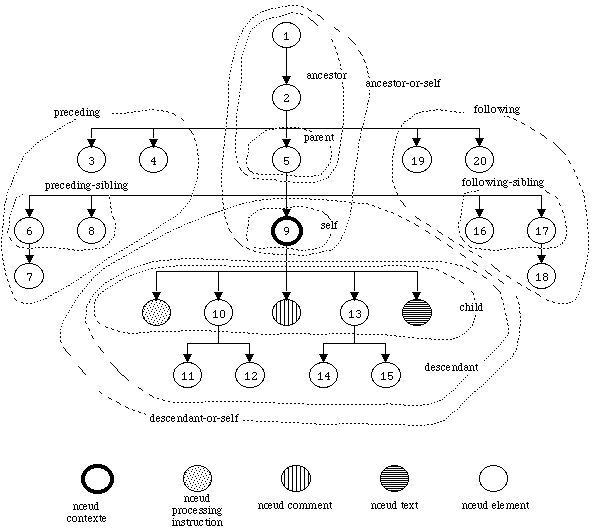
| Figure 14 : Reprťsentation des axes de localisation en tant qu'ensembles. |
Mentionner un axe de localisation dans
une ťtape de localisation permet d'obtenir un node-set
initial, qui sera ensuite progressivement ťlaguť sous
l'action du dťterminant (Node Test) puis des prťdicats.
L'idťe est donc qu'un axe de localisation reprťsente une
premiŤre approximation de ce que l'on veut, en se basant sur
la notion de voisinage du nœud contexte : les enfants,
les frŤres, les ascendants, etc. : on choisit ce qui se
rapproche le plus du node-set souhaitť, quitte ensuite ŗ
filtrer les nœuds en trop. L'approximation doit
toujours se faire par excŤs, puisqu'il est possible de
filtrer, mais pas d'ajouter.
Etant donnť un nœud-contexte, un axe est donc un
ensemble de nœuds, partageant une propriťtť commune
vis-ŗ-vis du nœud contexte.
Le standard XPath dťfinit treize axes de localisation. Les onze premiers sont construits ŗ partir du nœud contexte sur la base de la relation parent-enfant, ce qui donne un arbre gťnťalogique presqu'identique ŗ l'arbre XML du document source : il ne manque que les nœuds de type attribute et namespace. Prťcisťment, les deux derniers axes correspondent aux attributs et domaines nominaux du nœud contexte, mais ils sont un peu ŗ part, puisqu'il n'y a pas de relation parent-enfant complŤte entre un nœud et ses attributs ou domaines nominaux (revoir ŗ ce sujet les sections Nœud de type attribute et Nœud de type namespace ).
Voici la liste de ces 13 axes :
On peut reprťsenter graphiquement (voir Figure 14) les ensembles de nœuds que forment les axes (les axes attribute et namespace ne sont pas montrťs, et l'un des nœuds element est pris arbitrairement comme nœud contexte).
|
| Figure 14 : Reprťsentation des axes de localisation en tant qu'ensembles. |
| Note |
| La Figure 14 est trŤs largement inspirťe d'un schťma extrait de "Practical Transformation Using XSLT and XPath", un support de cours et un livre sans nom d'auteur (copyright 1998-2001 Crane Softwrights Ltd.) dont un extrait est disponible sur www.cranesoftwrights.com/training/. |
On voit sur la Figure 14 que l'axe child d'un ťlťment peut contenir des nœuds de type element, mais aussi de type processing instruction, text, ou comment. Afin de pouvoir trier, on dispose de possibilitťs de tests adťquats (voir Dťterminant (Node Test) ).
D'autre part, les numťros des nœuds sur cette figure correspondent ŗ l'ordre d'apparition de leur balise ouvrante, lors de la lecture sťquentielle du document XML correspondant, qui ressemble donc ŗ ceci (le nœud 9 est le nœud contexte) :
<1>
<2>
<3/>
<4/>
<5>
<6>
<7/>
</6>
<8/>
<9>
<? processing-instruction ?>
<10>
<11/>
<12/>
</10>
<!-- commentaire -->
<13>
<14/>
<15/>
<13/>
un texte
</9>
<16/>
<17>
<18/>
</17>
</5>
<19/>
<20/>
</2>
</1>
|
| Remarque |
| Sur la Figure 14, on voit le node-set self, qui ne comporte qu'un seul ťlťment. Pourtant, cet ťlťment possŤde une descendance assez nombreuse : il est important de rťaliser qu'un node-set peut trŤs bien contenir un ťlťment sans pour autant contenir les enfants ou la descendance de cet ťlťment. Mais ce n'est pas interdit non plus : voir par exemple le node-set descendant-or-self. |
Les axes parent, ancestor, ancestor-or-self, preceding, et preceding-sibling ne contiennent
que des nœuds situťs avant
(par rapport au nœud contexte) dans l'ordre de lecture
du document : on les nomme axes
rťtrogrades.
Tous les autres axes (y compris les axes attribute et namespace) ne contiennent que
des nœuds situťs aprŤs (par rapport au nœud
contexte) dans l'ordre de lecture du document : on les nomme
axes directs.
L'ordre de lecture du document, pour les attributs et les domaines nominaux, est un peu arbitraire par certains cŰtťs. La rŤgle est celle-ci : les attributs et domaines nominaux viennent aprŤs leur ťlťment parent, et avant les enfants de ce parent (ce qui est somme toute parfaitement logique, et correspond effectivement ŗ l'ordre de lecture du document). Ce qui est arbitraire, c'est que les domaines nominaux viennent avant les attributs (c'est une simple convention). Mais aucun ordre de lecture de document n'est dťfini pour classer les attributs entre eux, ni les domaines nominaux entre eux, car l'ordre dans lequel ils apparaissent n'est pas censť Ítre signifiant (cette propriťtť est imposťe par XML).
On dťfinit aussi une numťrotation des nœuds relative ŗ un axe, dont les numťros, appelťs indices de proximitť, commencent toujours ŗ 1.
Pour un axe direct (par. ex. child ), les indices de proximitť augmentent quand on s'ťloigne du nœud contexte en suivant l'ordre de lecture du document, alors que pour un axe rťtrograde (par. ex. preceding-sibling ), les indices de proximitť augmentent quand on s'ťloigne du nœud contexte dans l'ordre inverse de lecture du document.
A titre d'exemple, reprenons la Figure 14 , et montrons les indices de proximitťs pour deux axes rťtrogrades (preceding, ancestor-or-self), et pour 2 axes directs (descendant, following). Ces indices de proximitť sont montrťs sur la Figure 15 (les anciens numťros sont rappelťs en plus petit, ŗ l'extťrieur de chaque cercle).
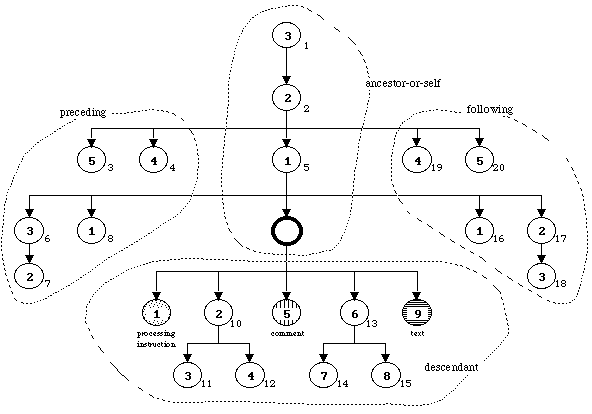 |
| Figure 15 : Indices de proximitť. |
| Remarque |
| Ces indices de proximitť
servent (entre autres) ŗ fournir, quand besoin est, un
ordre d'ťnumťration. Un node-set, rappelons-le, est un
ensemble, et ŗ ce titre, n'est pas ordonnť. Pas
ordonnť, cela signifie que l'ordre d'ťnumťration des
ťlťments n'est pas une propriťtť discriminante
lorsqu'on cherche ŗ distinguer deux ensembles : les
ensembles {x,y} et {y,x} sont indiscernables. Ceci ťtant, lorsqu'on ťnumŤre un node-set, par exemple pour traiter chacun de ses ťlťments un par un, il faut bien choisir un premier, un deuxiŤme, etc. jusqu'ŗ un dernier. Donc mÍme si un node-set n'est pas ordonnť, il est certainement utile, dans la pratique, d'avoir ŗ sa disposition un algorithme d'ťnumťration. |
La rŤgle, pour un node-set intervenant dans une ťtape de localisation, est que les indices de proximitť donnent l'ordre d'ťnumťration.